




W pierwszym artykule powiedzieliśmy na czym polega pełny odczyt tabeli i czym się różni od odczytu rekordów poprzez indeksy. Udało nam się też zauważyć niezwykłą rzecz. Na tej samej tablicy testowej teoretycznie opłacało się używać jednego z indeksów jeszcze przy szukaniu 15% rekordów, drugi natomiast był zbędny już przy 0,07%. Skąd bierze się takie zjawisko, czy faktycznie przekłada się ono na czas wykonywania zapytań i co możemy z tym zrobić?
Udostępnij!
Przyczyny
Aby zrozumieć zaobserwowane zjawisko, musimy zwrócić uwagę na następujące fakty:
Oś X w naszych wykresach jest wyskalowana procentami rekordów – i słusznie, ponieważ w SQL tabelę traktujemy jako ich abstrakcyjny zbiór abstrahując od warstwy fizycznej. Jeśli w tabeli z danymi osobowymi mamy 1% Kowalskich, myślimy kategoriami rekordów – natomiast koszty biorą się nie z przetwarzania ich tylko bloków, a zatem na warstwie fizycznej możemy sobie wyobrazić dwa skrajne przypadki:
1% rekordów może się przekładać na 1% bloków w tabeli (dobry indeks); koszty szukania Kowalskich są wtedy małe.
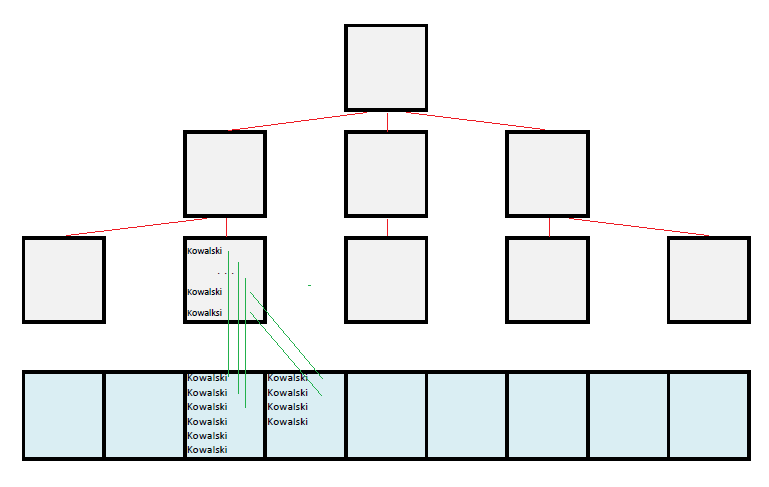
1% rekordów może się także przekładać na 100% bloków tabeli (zły indeks); koszty szukania tej samej liczby rekordów są wtedy duże.
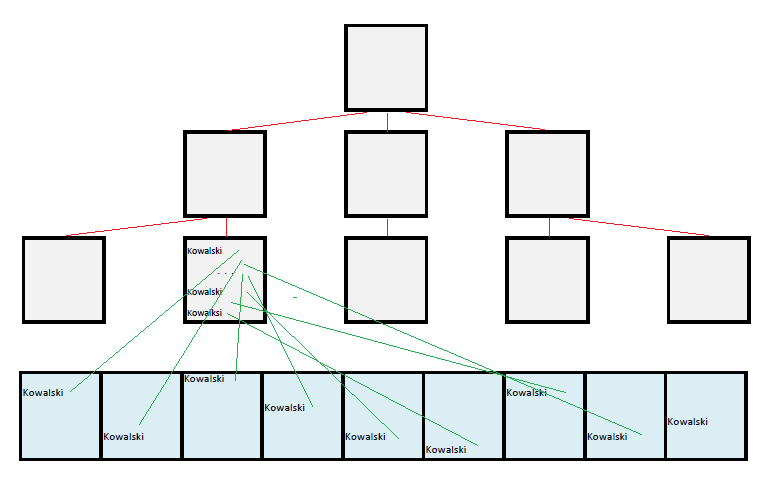
Paradoksalnie okazuje się więc, że najważniejsza cecha indeksu wcale nie zależy od niego tylko od tabeli, na której jest założony, a dokładniej od fizycznej kolejności w jakiej rekordy są składowane w tablicy, na co najczęściej nie zwracamy żadnej uwagi.
A co w sytuacji, gdy poszukuję 100% rekordów? Taka liczba to w najlepszym wypadku 100% bloków tabeli. Ile takich bloków muszę w takim razie przeczytać używając złego indeksu? Korzystając z indeksu jesteśmy niestety zobligowani do czytania rekordów w określonej kolejności narzuconej przez posortowane wartości z liści indeksu. Załóżmy, ze w pierwszym bloku znajduje się sześć rekordów: Nowak, Kowalski, Malinowski, Wojtkowiak, Pasko i Adasiewicz. W indeksie wartości te ułożą się alfabetycznie, w tabeli za to przypadkowo – patrz rysunek poniżej.
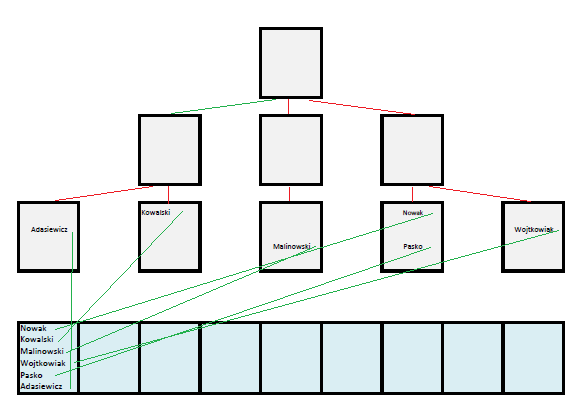
Do bloku numer jeden musimy więc sięgać sześć razy na różnych etapach wykonywania zapytania. Jeżeli podobna, chaotyczna sytuacja występuje w innych blokach tabeli, będziemy musieli przeczytać 600% bloków dla 100% rekordów – jeśli zaś rekordów jest 100, w najgorszym wypadku będziemy musieli przejrzeć 10000% bloków.
Jak to zmierzyć?
Wiemy już, że jeśli rekordy w tabeli są uporządkowane fizycznie według kolumny, na której znajduje się indeks, to indeks ten jest dobry, jeśli natomiast panuje chaos, indeks jest zły. Ale jak to dokładnie zmierzyć? Musimy zajrzeć do statystyk indeksu.
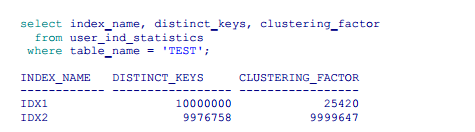
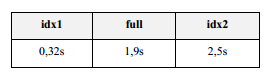
Jak widać w wynikach zapytania, selektywność kolumn kol1 i kol2 jest mniej więcej taka sama dla obu indeksów (obie kolumny unikalne lub prawie unikalne), ogromna dysproporcja występuje natomiast w wartości współczynnika CLUSTERING_FACTOR.; im mniejszy jest, tym lepiej. Znaleziona w tej statystyce liczba oznacza, ile bloków musimy przeczytać w tabeli, jeśli będziemy chcieli poznać wszystkie rekordy w kolejności narzuconej przez dany indeks. Dobry indeks będzie miał zatem clustering_factor na poziomie liczby bloków w tabeli (każdy blok czytany tylko jeden raz), a najgorszy na poziomie liczby wierszy (na potrzeby każdego wiersza trzeba indywidualnie przejrzeć cały blok; nic nie da się „załatwić przy okazji”).
Liczbę wierszy i bloków znajdziemy w statystykach tabeli:

Czy teoria przekłada się na praktykę?
Wielokrotnie na szkoleniach spotykałem się z opinią, że to wszystko to tylko takie teoretyczne bajanie, a w praktyce i tak opłaca się używać indeksów do 7-8%, bo kiedyś ktoś tak napisał w Internecie.
Cóż, przeprowadźmy prosty test. Spróbujmy wykonać zapytanie, które zwróci nam 2% rekordów dla pełnego odczytu, indeksu złego i indeksu dobrego.
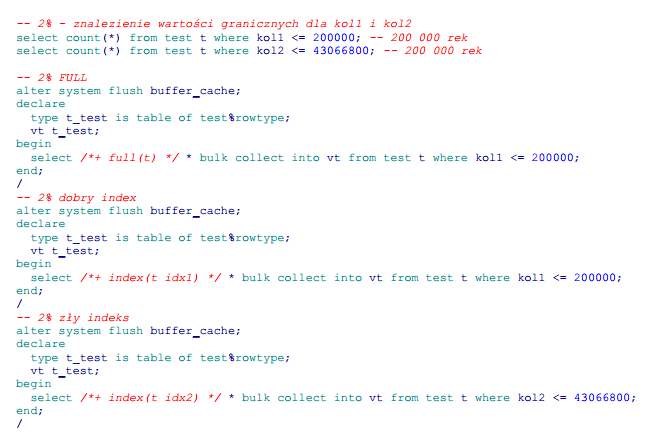
Podsumowanie wyników:
Na laboratoryjnej tabeli wyniki te nie rzucają na kolana; zauważmy jednak, że dobry indeks działa około 8x szybciej, co jest już niebagatelną wartością. Z kolei porównując z full scanem tabeli, zły indeks w ogóle nie powinien być brany pod uwagę przy 2%.
Jak naprawić zły indeks?
Wiemy już, że jakość indeksu oraz kolejność fizycznego składowania wierszy mają niebagatelne znaczenie. Najczęściej jest ona powiązana z kolejnością wkładania rekordów do tabeli. Możemy więc przewidywać, że najlepsze możliwe indeksy w naturalny sposób pojawią się na wszystkich kolumnach kluczy głównych zasilanych z sekwencji – wartości rosną bowiem regularnie w kolejnych rekordach. Często dotyczy to również kolumn z datami, pod warunkiem, że ich wartości korelują z czasem wstawienia rekordu.
Dobry indeks na datach przyda się zawsze, bo często tak filtrujemy, ale indeksów na kluczach głównych używamy praktycznie tylko przy szukaniu pojedynczego rekordu (filtrując lub łącząc tabele), kiedy to, czy indeks jest dobry, czy zły nie ma znaczenia. Oznacza to, że najlepsze indeksy w naszym repozytorium się marnują.
Czy możemy zatem „naprawić” indeksy? Oczywiście, że tak – wystarczy fizycznie poprzekładać rekordy w tabeli tak, aby były posortowane według kolumny indeksowanej. Należy jednak pamiętać, że „naprawiając” jeden indeks, na którym zależy nam najbardziej, zmieniamy również (na lepsze albo gorsze) wszystkie pozostałe na tabeli.
Przypuśćmy jednak, że na indeksie idx2 zależy nam szczególnie, ponieważ często wykonujemy na nim zapytania zakresowe lub też używamy go do wsparcia sortowań, czy też w celu uzyskania szybkiego pierwszego wiersza, indeks idx1 jest natomiast używany głównie do zapytań o konkretną wartość, a więc nie zależy nam na jego jakości.
Co możemy zrobić? Istnieją dwie opcje.
Offlinowe wyjęcie danych z tablicy, włożenie ich ponownie i sortowanie.

Powyższy scenariusz może być kłopotliwy; musi być robiony offline, często wymaga wyłączenia kluczy i zabiera wiele czasu.
Jeśli jednak mamy przynajmniej wersję oracle 12R2, możemy sobie uprościć życie za pomocą polecenia:
![]()
Powoduje ono, że system zapamiętuje w jakiej kolejności chcemy mieć rekordy w tabeli; od tej pory każda operacja MOVE na tali będzie je układać właśnie tak.
![]()
Nie tylko reorganizacja będzie prostsza, ale także będzie można ją wykonać szybciej i online.
Po wykonaniu jednego z powyższych scenariuszy i przeliczeniu statystyk, clustering_fuctor naszych indeksów prezentuje się tak:
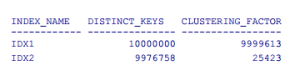
Kiedy powtórzymy test praktyczny, wyniki będą następujące:
Jak widać, udało się znacznie poprawić indeks idx2, ale zaowocowało to również zmianami na innych indeksach – w naszym wypadku pogorszeniem indeksu idx1.



