




W pierwszym artykule opisałem stan rzeczy przed ukazaniem się wersji 12c oraz nowe możliwości jakie zostały wreszcie wprowadzone w ramach autoinkrementacji. Teraz pora na zupełnie nowe funkcjonalności związane z nadawaniem identyfikatorów.
Udostępnij!
Sekwencje lokalne – raczej niepotrzebny gadżet
Wersja 12c daje nam jeszcze jedną nowinkę, a mianowicie sekwencje, w których numeracja jest unikalna tylko w obrębie jednej sesji. Trochę tak jak w GTT: definicja obiektu jest permanentna, ale każda sesja ma prywatną i tymczasową zawartość.
Zobaczmy na przykładzie.

Na podstawie nowej kolumny w user_sequences możemy rozróżnić typ sekwencji.
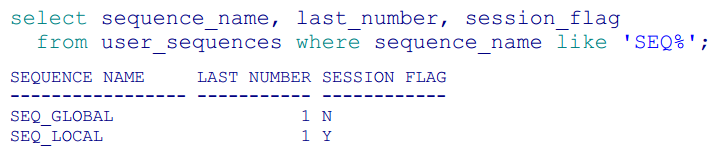
W działaniu obie sekwencje początkowo wyglądają podobnie.

Z poziomu innej sesji lub po przelogowaniu sekwencja lokalna resetuje się.
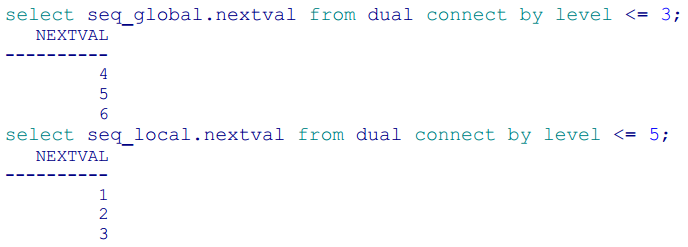
Jak widać, każda sesja w tym samym czasie posiada swój własny, niezależny generator unikalnych liczb. Pozwala on zachować unikalność tylko w obrębie sesji, ale za to nie jest częścią bazy danych, tylko instancji. Daje to nam szybszy dostęp do kolejnych numerów, a także sprawia, że równoległe procesy pobierające numery nie muszą rywalizować o dostęp do tego samego zasobu.
Sprawdźmy w znanym już scenariuszu, na ile zastosowanie lokalnej sekwencji przyspieszy nam wstawianie wierszy?

Dwukrotne przyspieszenie w porównaniu ze standardową sekwencją robi wrażenie. Pamiętajmy, że głównym atutem lokalnych sekwencji jest to, że w środowisku transakcyjnym wiele procesów nie konkuruje o ten sam zasób, czego w prostym eksperymencie niestety nie jestem w stanie pokazać.
Zastanówmy się, po co nam sekwencje lokalne? Ja widzę dwa zastosowania:
- Pierwsze i oczywiste to GTT – skoro zawartość tabel tymczasowych jest lokalna, to po co nam klucz unikalny globalnie, a skoro sekwencje lokalne działają zdecydowanie szybciej niż globalne….
- Drugie zastosowanie: jeśli w ramach sesji wzbogacimy klucz unikalny o prefix lub postfix z unikalnym identyfikatorem sesji, dostaniemy wartość unikalną globalnie, tylko, że szybciej. W dodatku unikniemy jeszcze jednego bardzo groźnego zjawiska, o którym napiszę w kolejnym rozdziale – tzw. gorącego bloku w indeksie. Dzięki prefixowi, każdy proces dostanie swój własny zakres generowanego numeru i procesy nie będą rywalizować o ten sam blok w indeksie założonym na kolumnę klucza głównego.
Dlaczego więc, cytując tytuł tego rozdziału, nazwałem sekwencje lokalne „raczej niepotrzebnym gadżetem”? Chodzi o to, że w obu powyższych, jakby nie było, istotnych scenariuszach, gdy unikalność jest potrzebna w ramach jednej sesji, to przecież równie dobrze (no, w pewnych sytuacjach może trochę mniej wygodnie) możemy się posłużyć zwykłą zmienną globalną procesu lub licznikiem wierszy dla operacji masowych. Zmierzmy jaki efekt wydajnościowy dzięki temu uzyskamy.

Skoro więc efekt podobny do tego wywołanego sekwencjami lokalnymi można uzyskać trzykrotnie szybciej, to raczej nie jest to przełomowa struktura w projektowaniu procesów.
18c i sekwencje skalowalne
Wersja 18c przynosi nam kolejną nowość rozwiązującą problem, który do tej pory musieliśmy obchodzić.
Wyobraźmy sobie następujący scenariusz: mamy tabelę z kluczem głównym i oczywiście indeksem, Bardzo wiele procesów równolegle do siebie wstawia do tej tabeli pojedyncze rekordy – co takiego może się stać? Po pierwsze, procesy te będą rywalizować o dostęp do sekwencji, ale na to niewiele poradzimy i nie to jest najgorsze. Najgorsze jest to, że sekwencja będzie cały czas dostarczała podobne wartości – w tabeli zostaną one umieszczone w dowolnym miejscu, ale w indeksie położenie klucza zależy od jego wartości. Wszystkie nowe rekordy będą zatem musiały być odnotowane w tym samym bloku indeksu i tu zrobi nam się ogromny korek, zwłaszcza, jeśli mamy RAC’a i poza rywalizacją procesów, o blok zaczną jeszcze walczyć instancje klastra.
W takim scenariuszu Oracle sugeruje założenie na klucz indeksu z odwróconym kluczem – to, owszem, działa, ale taki indeks traci sporo ze swojej funkcjonalności. Nie można już sortować, nie można robić full/range scanu, nie zadziała tez skip scan i min/max scan.
Moglibyśmy również, nie tracąc funkcjonalności indeksu, obejść problem oprogramowując inserty w sposób wspomniany w poprzednim rozdziale przy okazji sekwencji lokalnych – przydzielając każdemu węzłowi klastra i każdej sesji pulę numerów generowanych z sekwencji. Rozwiązanie to jest jednak skomplikowane i pracochłonne; tyle, że od wersji 18c mamy je gotowe i nie musimy nic robić, poza wyborem odpowiedniego typu sekwencji.
Idea wspomnianych w tytule rozdziału sekwencji skalowalnych jest banalnie prosta. Numer wygenerowany z sekwencji zawiera trzy sklejone składniki:
- numer instancji (zwiększony o 100, żeby nie było wiodących zer)
- SID sesji
- unikalny numer generowany globalnie jak dotychczas.
Dzięki powyższej zasadzie, każdy węzeł RACa, a w ramach każdego węzła każdy proces, ma swoją pulę numerów, a więc swój własny kawałek indeksu, w którym nie musi z nikim współzawodniczyć o modyfikacje zawartości bloków.
Jak to wygląda w praktyce?
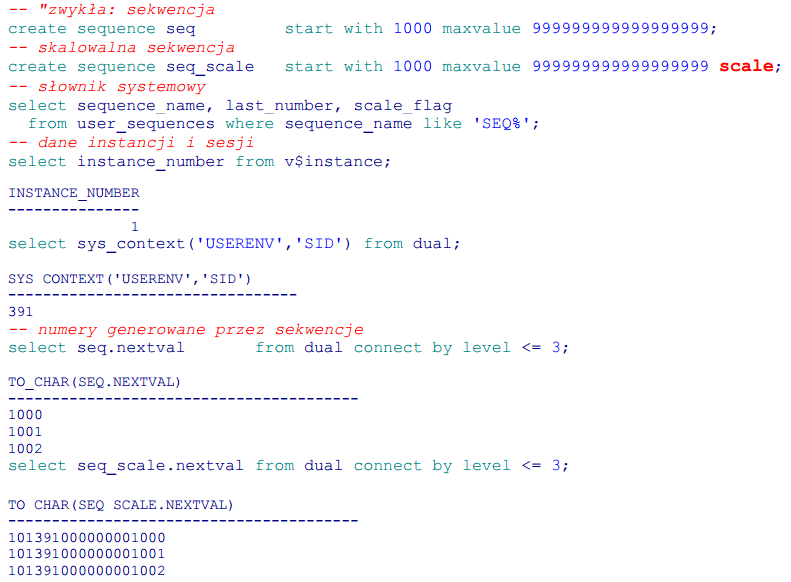
Czy są jakieś minusy? Na pewno objętość kolumny klucza. Weźmy powyższe przykładowe wartości z obu sekwencji.
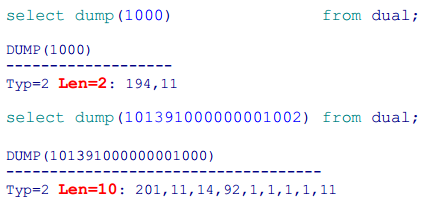
To z kolei rozedmie nam każdą tablicę z kluczem głównym oraz wszystkie tablice z kluczami obcymi, które odnoszą się do tak dużych wartości liczbowych.
Mam nadzieję, ze te nieco przydługie rozważania o sekwencjach w Oracle choć trochę zaciekawiły czytelników. Zapraszam do śledzenia innych moich tekstów zamieszczanych na blogu.



