Projektując procesy zachodzące podczas przetwarzania danych bardzo często musimy korzystać z ich tymczasowych zbiorów – powołujemy je do życia podczas wstępnej fazy procesu, a następnie sięgamy po nie na kolejnych etapach. Po zakończeniu musimy jeszcze pamiętać o pozbyciu się zbędnych już danych, co ze względów wydajnościowych i technicznych (gdy np. z powodu błędów proces kończy się przed czasem) również bywa problematyczne.
Udostępnij!
W zależności od szczegółowych wymagań, w kwestii procesowania danych tymczasowych możemy rozpatrzyć następujące warianty.
Dane tymczasowe w zwykłej tablicy
Najprostszym, ale niestety również najmniej efektywnym rozwiązaniem dla danych tymczasowych jest zwykła tablica; możemy w niej wyłączyć logowanie do dziennika powtórzeń opcją lub hintem nologging). Poniższy rysunek pomoże nam zrozumieć zjawiska zachodzące w takiej tabeli.
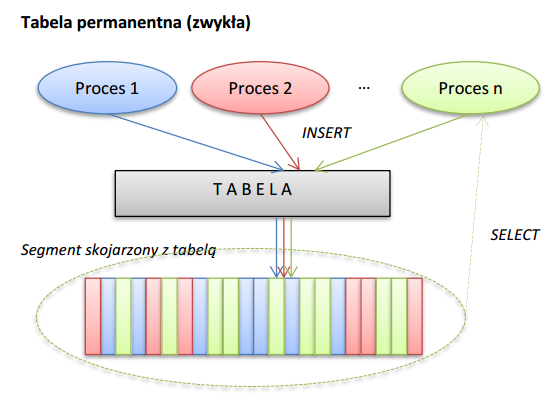
Używając klasycznej tabeli z danymi tymczasowymi spotkamy się z czterema głównymi problemami:
- Po zatwierdzeniu danych tymczasowych będą one widoczne dla innych procesów –żeby uniknąć przetwarzania „ cudzych” danych, każdy proces będzie musiał posiadać własny identyfikator i podpisywać nim swoje rekordy. W efekcie proces się skomplikuje, a zbiór danych niepotrzebnie powiększy się o identyfikatory procesu (ok 6-7 bajtów na rekord).
- Kiedy po zakończeniu przetwarzania danych chcemy je usunąć, nie możemy obciąć tabeli poleceniem truncate, ponieważ ryzykowalibyśmy wtedy eliminację cudzych – musimy więc czyścić je transakcyjnym poleceniem delete, co pochłania dużo czasu i zasobów.
- Mimo, że procesujemy dane tymczasowe, umieszczając je w „normalnej” tabeli powodujemy, że system niepotrzebnie zapewni im bezpieczeństwo na wypadek awarii, a więc będzie logował operacje na nich do plików dziennika powtórzeń. Opcja nologging działa wyłącznie dla masowych insertów ścieżką bezpośrednią – inne operacje DML cały czas są logowane.
- Jeżeli wiele instancji procesu korzysta jednocześnie z tej samej tablicy, ich dane niestety fizycznie trafiają do jednego worka (segmentu), w którym mieszają się ze sobą. Jeżeli proces chce potem przetworzyć własne dane, przy tworzeniu zapytania musi przebierać w danych wszystkich instancji. Koszty przetwarzania są więc proporcjonalne do ilości danych wszystkich instancji, a nie do własnych.
Dlaczego zatem bierzemy w ogóle pod uwagę zwykłą, permanentną tablicę jako miejsce na dane tymczasowe? Jeżeli chcemy, aby nasze dane były dostępne dłużej niż czas trwania jednej sesji, musimy z niej skorzystać.
Globalne Tablice Tymczasowe – GTT
Aby uniknąć opisanych powyżej problemów, możemy użyć Globalnych Tablic Tymczasowych (pod warunkiem, że nie dotyczy nas ograniczenie wspomniane na końcu poprzedniego punktu).
Poniższy rysunek tłumaczy działanie Globalnych Tablic Tymczasowych poprzez porównanie ich ze zwykłymi tabelami.
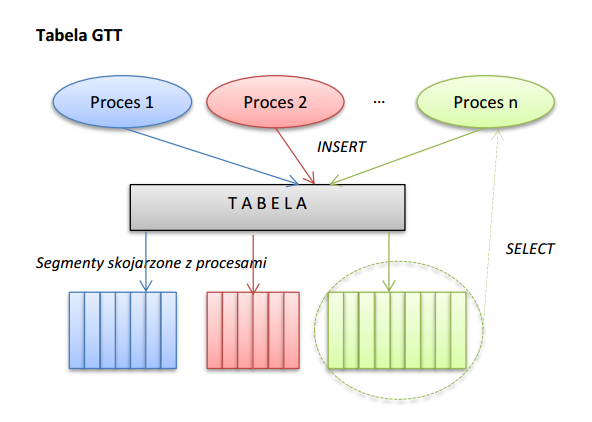
Tabele GTT posiadają permanentną definicję – dopóki nie zostaną usunięte, raz założone, nie znikają. Tak samo jak zwykłe tabele:
- mogą być indeksowane
- mogą posiadać constrainty
- mogą być używane w PL/SQL podczas kompilacji
- można im nadawać uprawnienia.
Główna różnica polega na tym, że sam segment przechowujący dane zostaje powołany do życia w momencie pierwszego insertu do tablicy. Jest on:
- prywatny dla procesu w sensie logicznym (proces widzi tylko swoje dane)
- prywatny dla procesu w sensie fizycznym (każdy proces ma swój własny, wyodrębniony fizycznie kawałek pamięci)
- tymczasowy – w zależności od opcji tabeli GTT, segment zostanie automatycznie zdealokowany , a dane znikną po zakończeniu sesji (opcja on commit preserve rows) lub transakcji (opcja domyślna on commit delete rows)
Co do problemów wymienionych przy zwykłych tablicach – nie musimy podpisywać rekordów, ponieważ każdy proces widzi tylko własne. Po zakończeniu przetwarzania (także awaryjnym) w ogóle nie usuwamy danych – znikną same. System jest świadomy ich tymczasowości, a więc przetwarza je szybciej nie musząc zabezpieczać się przed awarią; każda instancja procesu „obrabia” fizycznie wyłącznie własne, wyizolowane dane.
Żeby nie było tak idealnie; pracując w wersji 11g lub niższej, musimy pamiętać, że na tablicach GTT nie wolno nam zbierać statystyk dla optymalizatora (chociaż jest to wykonalne), ponieważ, tak samo jak definicja tabeli, są one wspólne dla wszystkich procesów. Zbierając statystyki z własnych danych wstrzykiwalibyśmy je pozostałym procesom, które mają swoje rekordy; doprowadziłoby to do do błędnej pracy CBO. Problem ten został rozwiązany dopiero w wersji 12cR1 poprzez wprowadzenie statystyk prywatnych dla każdej sesji (system sam rozpoznaje, że ma do czynienia z tablicą GTT i ustawia odpowiedni typ statystyk).
Prywatne Tablice Tymczasowe (lokalne) – PTT
W wersji 18g został wprowadzony jeszcze jeden wariant składowania danych tymczasowych – szczególnie mocno oczekiwały na niego osoby, które „przeprowadzały” się z MS SQL’a, gdzie analogiczna struktura jest podstawą przetwarzania danych w tamtejszym T-SQL’u.
Poniższy rysunek przedstawia ideę prywatnych tabel tymczasowych.
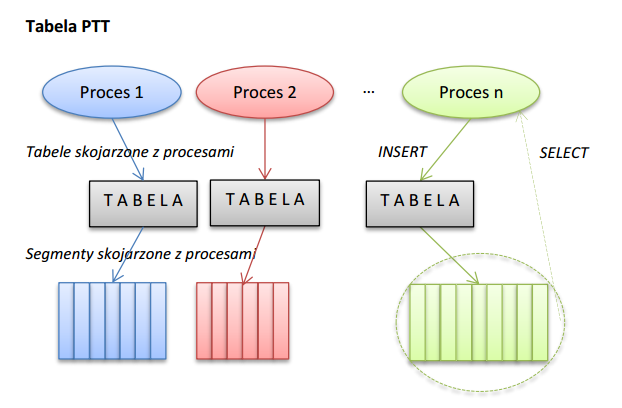
W przypadku PTT nie tylko zawartość, ale również definicja tabel jest tymczasowa i prywatna. Na czas trwania sekcji lub transakcji każdy proces może powołać do życia własną tabelę. Jej nazwa nie koliduje z tabelami innych procesów, ponieważ widoczność definicji jest ograniczona do sesji/transakcji, która tę tabelę utworzyła.
Używając tabel PTT należy dodatkowo liczyć się z pewnymi ograniczeniami:
- Nazwa tabeli musi się rozpoczynać od ściśle określonego prefixu – znajdziemy go w v$parameter pod nazwą private_temp_table_prefix. Domyślnie jest to ORA$PTT_.
- Zwykłe obiekty bazodanowe, np. procedury, widoki lub inne tabele, nie mogą się odwoływać do PTT poprzez FK.
- Nie można tworzyć snapshotów i indeksów.
- Zbieranie statystyk dla CBO jest mocno ograniczone.
Do PTT nie można odwoływać się przez db link.
Dochodzi do tego jeszcze sporo drobiazgów wynikających z nietypowej formy tych tabel.
Porównanie tabel permanentnych – GTT i PTT
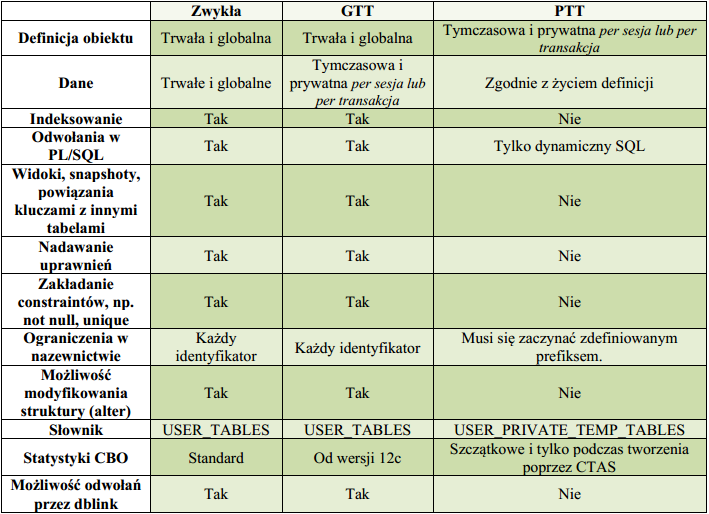
Na sam koniec przedstawimy krótkie porównanie najważniejszych cech trzech omawianych rodzajów tabel.