




Intelligent Query Processing nie jest całkowicie nową funkcjonalnością.
Udostępnij!
Stanowi rozwinięcie zaprezentowanej w MS SQL 2017 technologii o nazwie Adaptive Query Processing, która składa się z:
- Batch mode memory grant feedback
- Batch mode adaptive join
- Interleaved execution
Te trzy funkcjonalności były wprowadzeniem do automatyzacji procesu optymalizacji zapytań. W zaprezentowanym rozwiązaniu:
- Batch mode memory grant feedback – był długo oczekiwanym sposobem przekazania do Query Procesor zwrotnej informacji o realnym wykorzystaniu przydziału pamięci przez zapytanie, a więc optymalizacją przydziału pamięci, aby uniknąć jej marnowania lub konieczności wykorzystania TempDB gdy przydział pamięci był zbyt mały.
- Batch mode adaptive join – umożliwił elastyczny dobór sposobu realizacji tego samego zapytania w zależności od ilości przetwarzanych rekordów, a więc lepsze wykorzystanie informacji zawartej w statystykach.
- Interleaved execution – był poważną próbą rozwiązania problemu MSTVF (multi-statement table-valued functions), gdzie do wersji SQL 2016 optymalizator zakładał, że taka funkcja zwróci jeden rekord, w SQL 2016 zakłada, że zwróci 100 rekordów, a w SQL 2017 cały proces został przebudowany. Zamiast jednokrotnego przebiegu Optymalizacja -> Wykonanie nastąpiła całkowita przebudowa procesu, gdzie MSTVF jest wykonywana jako pierwszy krok, a dopiero po jej wykonaniu jest tworzony plan dla pozostałej części zapytania.
Obecnie zostały dodane kolejne funkcjonalności:
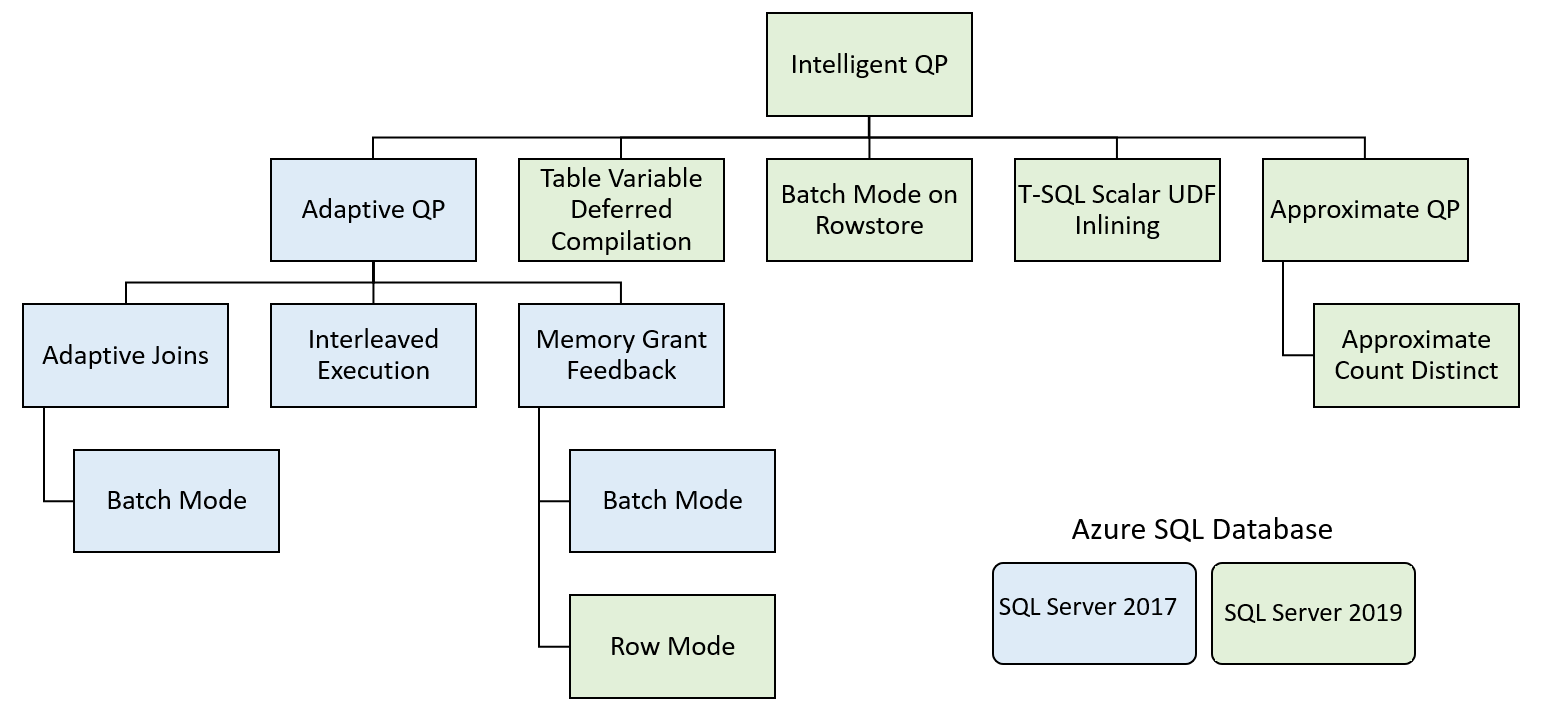
- Table Variable Deferred Compilation – bardzo ważna funkcjonalność pozwalająca na wykorzystanie realnej liczności zmiennej tabelarycznej podczas tworzenia planu wykonania zapytania.
- Batch Mode on Rowstore – rozwinięcie możliwości przetwarzania wsadowego dla zwykłych tabel, a nie tylko columnstore.
- T-SQL Scalar UDF Inlining – rozwiązanie wykorzystujące mechanizm FROID, który pozwala na analizę kodu funkcji skalarnej i próbę jej zastąpienia przez odpowiednie zapytanie na bazie operacji na zbiorach.
- Approximate QP realizowany poprzez Approximate Count Distinct – czyli bazujące na algorytmie Flajolet-Martin rozwiązanie HyperLogLog pozwalające poprzez oszacowanie podzbiorów podać interesującą nas wartość dla całego zbioru.
Jak wynika z tego krótkiego przeglądu, wysiłki firmy Microsoft koncentrują się na dodatkowym wsparciu dla Query Procesor w miejscach, które od „zawsze” były wskazywane jako problematyczne.
Ponieważ wszystkie te nowości są dość istotne, w kolejnych wpisach postaram się dokładniej przybliżyć ich funkcjonalność, zaczynając od nowości wdrożonych w SQL Server 2017.



